A little closer to Cook’s distance
How outliers can affect your model performance?
“Observation which deviates so much from other observations as to arouse suspicion it was generated by a different mechanism” — Hawkins(1980)

Cook’s distance and outliers? How can they relate to each other?
In statistics, Cook’s distance (often referred to as Cook’s D) is a common measurement of a data point’s influence. It’s a way to find influential outliers in a set of predictor variables when performing a least-squares regression analysis. The concept was introduced by an American statistician named R. Dennis Cook, hence it was called after him.
Formula:

yj — the jth fitted response value.
yj(i) — the jth fitted response value, where the fit does not include observation i
p — the number of regression coefficients
σ — the estimated variance from the fit, based on all observations, i.e. Mean Squared Error
Simply said, Cook’s D is calculated by removing the ith data point from the model and recalculating the regression. All the values in the regression model are then observed whether changes have been detected after the removal of the point. This is an iterative way of examining the influence of that observation.
The cut-off values — controversial:
It sounds logical. However, how can one tell that a point is an outlier? Similarly as when we say something is big, how big is big? How can we define big?
There are several arguments regarding this matter, such as:
- If a data point has a Cook’s distance of more than three times the mean, it is a possible outlier
- Any point over 4/n, where n is the number of observations, should be examined
- To find the potential outlier’s percentile value using the F-distribution. A percentile of over 50 indicates a highly influential point
For simplicity, a operational guideline of Di > 1 has been suggested which means that if a Di value of more that 1, it indicates an influential value was found. But you may want to look at values above 0.5.
Sidenote — Note that the Cook’s distance measure does not always correctly identify influential observations. John Fox (1991) in his book Regression Diagnostics: An Introduction explained that a point can only be seen as a potential outlier if it visually stands out from the rest of the data.
When to use Cook’s D
- When suspect influence problems
- When graphical displays may not be adequate
- When performing a least-square regression analysis
Implementation of Cook’s distance in Python
For the purpose of setting an example, I have used the dataset from King County House Sales.
First, we build an OLS model with Statsmodels library. Then check the regression plots and Q-Q plots.

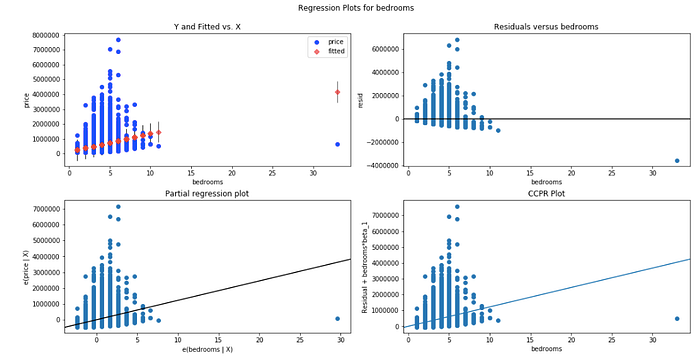
To highlight the code for displaying the summary frame is as below:
from statsmodels.formula.api import ols
infl = model.get_influence()
sm_fr = infl.summary_frame(); sm_fr[:10]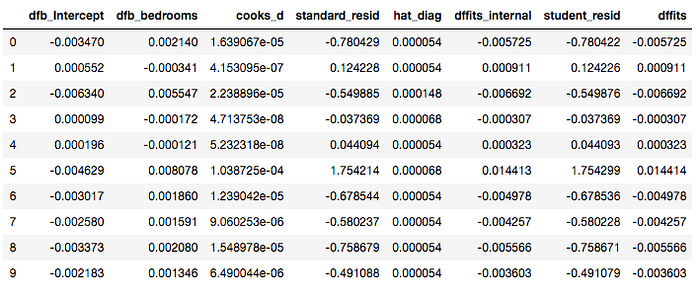
How to interpret Cook’s Distance plots
From the summary frame, we could visualise the Cook’s distance or find the point with the highest value of Cook’s distance. Or we could visualise it by other library — Yellowbrick library.
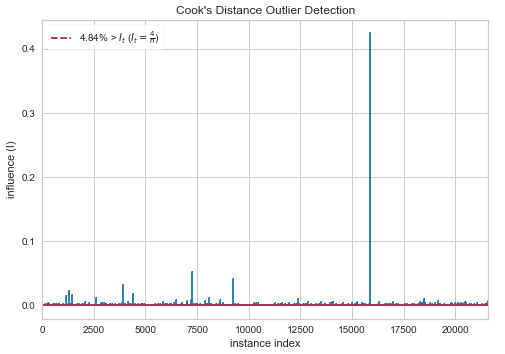
Notice that even though the point from the graph does not have a Cook’s distance of more than 0.5 nor 1, we could tell that it is indeed an outlier.
The graph shows that the outlier has the index of above 1500. We can check for the maximum value in column “bedrooms” and check the its index with:
df.bedrooms.max() #output: 33df.bedrooms.idxmax() #output: 15856df.drop(df.loc[df['bedrooms']==33].index, inplace=True) #dropping the row from the bedrooms columnf = 'price~bedrooms'
model = smf.ols(formula=f, data=df).fit()
model.summary() #running the OLS model again
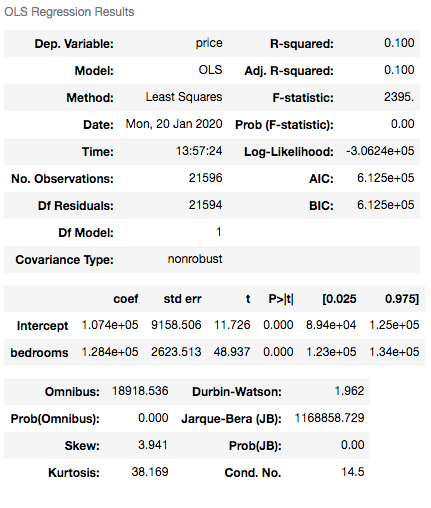
Even though, the outlier has been detected, it is rather our decision to either remove it or to investigate it further.
Other case of influence statistics
Leverage — the proportion of the total sum of squares of the explanatory variable contributed by the ith case.
Studentised residual — the studentised residual for an observation is closely related to the error of prediction for that observation divided by the standard deviation of the errors of prediction
The use of leverage and studentised residual — help explain the reason for influence , unusual x-value, outlier or both; helps in deciding the course of action outlined in the strategy for dealing with suspected influential cases.
References
http://www.columbia.edu/~so33/SusDev/Lecture_5.pdf
